2.1 SQL Basics
2.1.1 Entity Relationship Diagrams (ERD)
This is a way to see (visualize) the relationship between different spreadsheets, in other words, how is structure a database. In a database, there are several tables, and each table has your own attributes, based on the cardinality they could interact with each other.
2.1.1.1 Entities
This is a simple spreadsheet with information about anything you want, but keep in mind to: store new observations by rows and features/variables by column.

This is a entity.
My example is a table called Marks, which has mark id, student id, subject id, date and mark as attributes. The other column is the variable’s type.
2.1.1.2 Atributte
An attribute is a feature we want to keep track.
2.1.1.3 Relationship
Is a way to connect two tables.
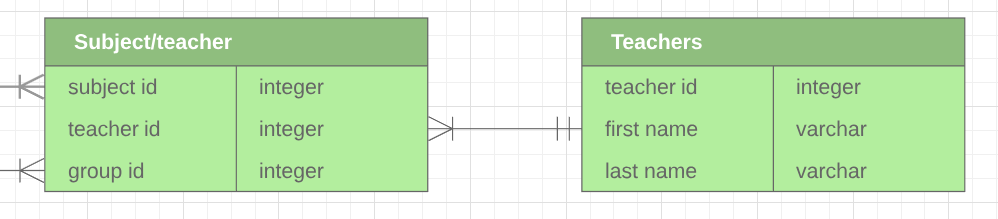
The line connecting two tables is a relationship.
Remember, this line has some properties, that is named as cardinality.
2.1.1.4 Cardinality
Cardinality represents a notation of how the information between tables will interact with each other.
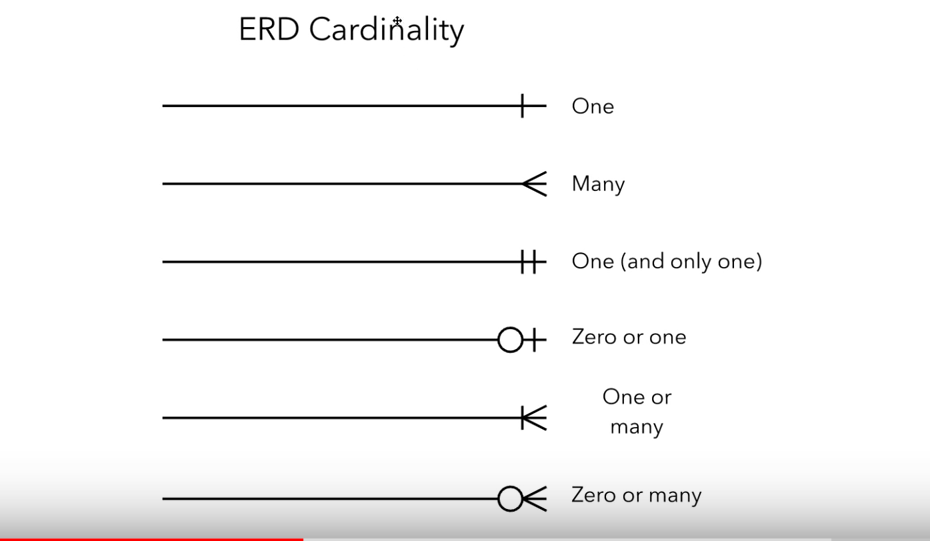
In a nutshell of Cardinality - Extracted from the Lucidchart Video.
Additional videos with good content.
Video 1 - Lucidchart Vídeo 2 - Lucidchart
2.1.2 SQL Introduction
SQL is a Language used to manage this interactions between tables, allowing us to access the stored database. The meaning of SQL is:
Structured Query Language
It is very popular in Data Analysis because:
- Easy to understand
- Easy to learn
- Used to access very large datasets directly where is stored
- Easy to audit and replicate
- It is possible to run multiple queries at onde
- Almost do not have a limit of rows/observations
- Ensure the data Integrity, it is not possible to register a half child if you have defined this field as an integer
- SQL is very fast
- Database provide the data sharing, everybody could access the data simultaneously, which is good due to a standardization of database
SQL provides also functions such as:
- Summation
- Count
- Max and min
- Mean, etc.
Have in mind, probably we are going to manipulate data, and rarely updating or change values.
SQL is not case sensitive, so the best practices is to write the clauses/staments in upper case.
Best practices
SELECT first_column
FROM my_tableBad one
SelecT first_column
from my_tableBear in mind, the indentation is not a requirements but helps a lot to understand your code.
2.1.2.1 SQL vs. NoSQL
Extracted from the class notes.
You may have heard of NoSQL, which stands for not only SQL. Databases using NoSQL allow for you to write code that interacts with the data a bit differently than what we will do in this course. These NoSQL environments tend to be particularly popular for web based data, but less popular for data that lives in spreadsheets the way we have been analyzing data up to this point. One of the most popular NoSQL languages is called MongoDB. Udacity has a full course on MongoDB that you can take for free here, but these will not be a focus of this program. NoSQL is not a focus of analyzing data in this Nanodegree program, but you might see it referenced outside this course!
2.1.3 Clauses
Tell the database what to do.
2.1.3.1 DROP TABLE
Remove a table from the database.
2.1.3.2 CREATE TABLE
Create a new table.
2.1.3.3 SELECT
Is also know as query, is used to create a new table with the selected variables. You can use * if you want to select all columns.
SELECT first_column, second_column, last_column
FROM first_table;2.1.3.4 LIMIT
This is the same of .head() but this could only load a few lines to analyses the table.
SELECT first_column
FROM my_table
LIMIT 1000 /* Will load the firs 1000 lines*/2.1.3.5 ORDER BY
It is possible to order by in ascendant and descendent way.
ascendant
SELECT first_column, second_column, last_column
FROM my_table
ORDER BY last_column /*ascendanting*/
LIMIT 1000descendent
SELECT first_column, second_column, last_column
FROM my_table
ORDER BY last_column DESC, second_column /*descending for last_column*/
LIMIT 1000This last query will returns:
- Last_column ordered by the highest to lowest;
- The second_column will be the lowest to highest.
2.1.3.6 WHERE
Apply a filter to find a specific customer or anything else.
SELECT first_column, second_column, last_column
FROM my_table
WHERE first_column = 100
ORDER BY second_column
LIMIT 100All staments possible to use. * > (greater than) * < (less than) * >= (greater than or equal to) * <= (less than or equal to) * = (equal to) * != (not equal to)
If the argument of the WHERE clause is not a number, you must use single quotes.
SELECT first_column, second_column, last_column
FROM my_table
WHERE first_column = 'Hello World!'
ORDER BY second_column
LIMIT 1002.1.4 Derived Columns
Is a new column created from the query. It is similar to the mutate function from R.
This is the operator to create a derived column:
*(Multiplication)+(Addition)-(Subtraction)/(Division)
SELECT id, (standard_amt_usd/total_amt_usd)*100
FROM orders
LIMIT 10;Will display without a specific name (?column?).
2.1.4.1 AS
If you use the AS the derived column will be name as you define (in other words “alias”).
SELECT id, (standard_amt_usd/total_amt_usd)*100 AS std_percent, total_amt_usd
FROM orders
LIMIT 10;Best pratices: No capital letters, descriptive names, etc.
2.1.5 Introduction to “Logical Operators”
In the next concepts, you will be learning about Logical Operators. Logical Operators include:
2.1.5.1 LIKE
Using with WHERE clause could search some patterns.
SELECT first_column, second_column, last_column
FROM my_table
WHERE last_column LIKE '%ello%'The % is called wild-card.
2.1.5.2 IN
It is the same in Python or R. IN will be used to filter the dataset based on a list.
SELECT first_column, second_column, last_column
FROM my_table
WHERE last_column IN (100, 200)This example will filter the rows of last_column with values of 100 or 200.
2.1.5.3 NOT
NOT return the reverse/opposite.
SELECT first_column, second_column, last_column
FROM my_table
WHERE last_column NOT IN (100, 200)This example will remove all observations equals to 100 or 200.
Possible uses:
- NOT IN
- NOT LIKE
2.1.5.4 AND
Logical statment usually to make some filtration.
SELECT *
FROM orders
WHERE standard_qty > 1000 AND poster_qty = 0 AND gloss_qty = 0;2.1.5.5 BETWEEN
Sometimes AND statment could be replaced by BETWEEN, this is much clearly to understand. BUT the BETWEEN is inclusive, which means the endpoints will be included in the filter.
SELECT name
FROM accounts
WHERE name NOT LIKE 'C%' AND name LIKE '%s';2.1.5.6 OR
Well, this is a logical operator.
SELECT id
FROM orders
WHERE gloss_qty > 4000 OR poster_qty > 4000;A work by AH Uyekita
anderson.uyekita[at]gmail.com