
![]()
O GridSearchCV é uma ferramenta usada para automatizar o processo de ajuste dos parâmetros de um algoritmo, pois ele fará de maneira sistemática diversas combinações dos parâmetros e depois de avaliá-los os armazenará num único objeto.
Foi disponinilizado o Jupter Notebook com detalhes pormenorizados do uso do GridSearchCV, bem como exemplos didáticos.
Resumo
- Exemplo disponibilizado em Jupyter Notebook através da plataforma binder;
- Aplicação do
GridSearchCVpara o tuning dos parâmetros; - Apresentação e configuração dos parâmetros
scoring,cverefit.
GridSearchCV
O GridSearchCV é um módulo do Scikit Learn (Leia mais sobre ele aqui) e é amplamente usado para automatizar grande parte do processo de tuning. O objetivo primário do GridSearchCV é a criação de combinações de parâmetros para posteriormente avaliá-las.
Jupyter Notebook
Há um arquivo Jupyter Notebook para acompanhar esse post com todos os detalhes de codificação.
Dataset
Será usado um toy dataset presente no próprio Scikit Learn para elucidação do GridSearchCV.
# Importação do dataset usado como exemplo
from sklearn import datasets
# Dados de Câncer de mama.
cancer = datasets.load_breast_cancer()
# Criação do dataset features e vetor labels.
features = cancer.data
labels = cancer.targetClassifier
Adota-se como algoritmo para ajustar os parâmetros o AdaBoost.
# Importação do AdaBoost.
from sklearn.ensemble import AdaBoostClassifier
# Uso do constructor do AdaBoost para criar um classifier.
clf = AdaBoostClassifier() # Sem nada dentro, pois vamos "variar" os parâmetros.Criação de Combinações de Parâmetros
Com base numa “lista”” de parâmetros o GridSearchCV criará as combinações e depois as avaliará, por exemplo, quero testar alguns valores de parâmetros de um AdaBoost. Os valores desta “lista” foram arbitrariamente escolhidos e sem nenhum critério técnico, o objetivo é encontrar valores otimizados.
# Exemplo dos parâmetros que quero testar.
parametros = {'n_estimators':[1, 5, 10],
'learning_rate':[0.1, 1, 2]}Note que foram dados 3 valores para n_estimators e 3 valores para learning_rate, logo haverá 9 combinações possíveis.
$$Combinacoes = 3 \cdot 3 = 9 \tag{1}$$
Possíveis combinações:
# Todas as combinações possíveis.
# combinacao_n = [n_estimators, learning_rate]
combinacao_1 = [1, 0.1]
combinacao_2 = [1, 1]
combinacao_3 = [1, 2]
combinacao_4 = [5, 0.1]
combinacao_5 = [5, 1]
combinacao_6 = [5, 2]
combinacao_7 = [10, 0.1]
combinacao_8 = [10, 1]
combinacao_9 = [10, 2]Portanto, sabe-se que o resultado do GridSearchCV deverá ter 9 linhas e a maneira de acessar essas informações é a partir do atributo .cv_results_.
Um exemplo de uso do GridsearchCV é exposto abaixo.
# Criação do objeto do GridSearchCV.
grid = GridSearchCV(estimator = clf, # É o nosso AdaBoost.
param_grid = parametros, # É aquele dicionário com valores para serem testados.
scoring = 'f1', # Arbitrariamente escolhi o f1, adiante explico com detalhes.
cv = 20) # Idem, arbitratiamente escolhi 20 e adiante será explanado.Após a criação do objeto do GridSearchCV, pode-se treinar e imprimir os resultados.
# Treinando o grid.
grid.fit(features, labels)
# Imprimindo os resultados.
pd.DataFrame(grid.cv_results_)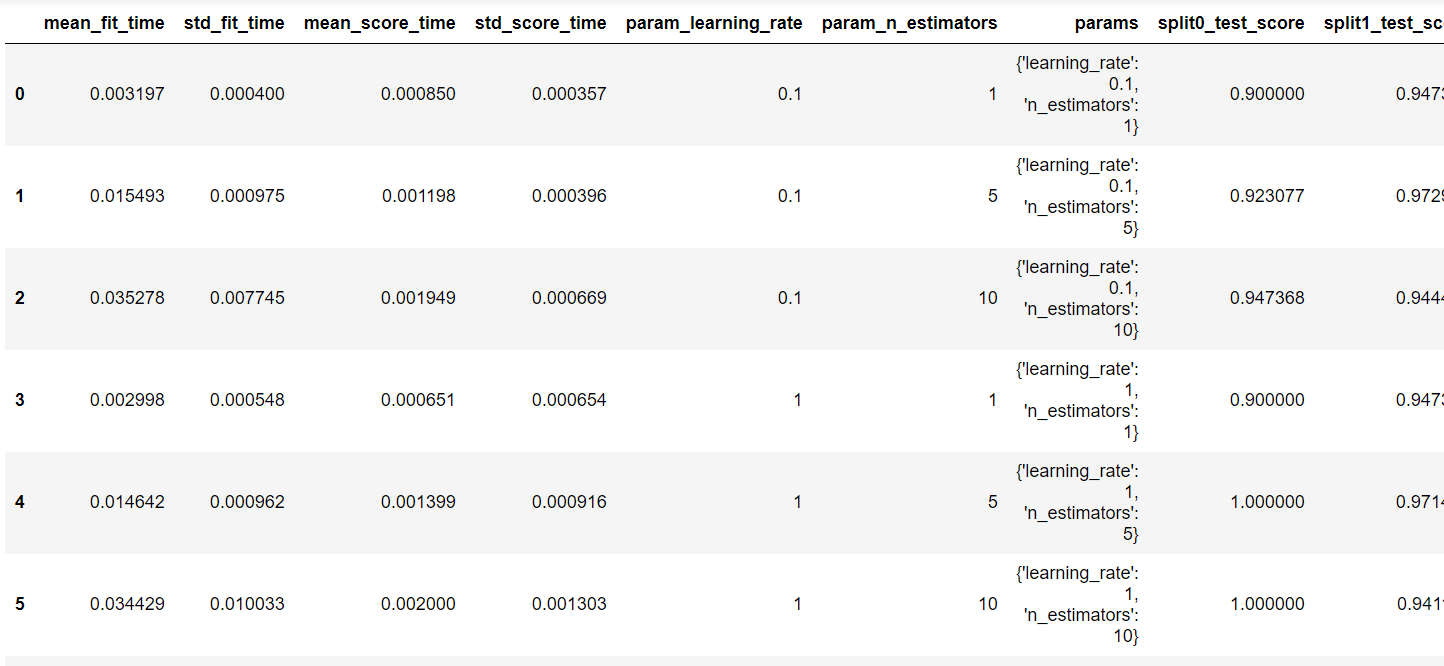
Há muitas colunas nesse resultado, então vamos fazer um subset escolhendo as colunas de interesse.
# Imprime colunas de interesse.
pd.DataFrame(grid.cv_results_)[['params','rank_test_score','mean_test_score']]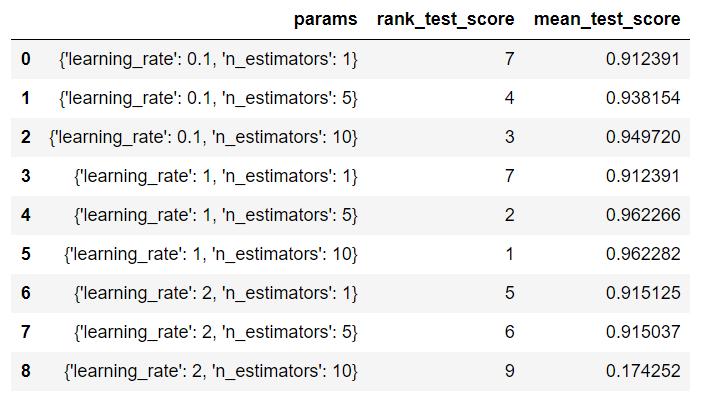
Conforme a tabela acima, o melhor resultado de f1 é produzido pelos parâmetros {'learning_rate': 1, 'n_estimators': 10}. O atributo .best_params_ pode ser usado também para obter os melhores parâmetros.
# Imprime os parâmetros que produziram o ".best_score_".
grid.best_params_Bem como é possível imprimir o valor de f1 usando o atributo .best_score_.
# Imprimindo o score.
grid.best_score_Que no caso será 0.9622818059600856
Cross Validation
Uma pequena revisão.
É o uso de um dataset independente para avaliar o grau e a capacidade de generalização do seu modelo.
Note que o objeto grid foi definido com cv = 20 e quando cv é um número inteiro o GridSearchCV executa um StratifiedKFolds, isso quer dizer que o dataset foi divido em 20 partes (ou folds) e cada parte foi usada como test em uma simulação.
# Exemplo para o uso do StratifiedKFolds com 5 folds.
grid_2 = GridSearchCV(estimator = clf,
param_grid = parametros,
cv = 5,
scoring = 'f1')
# Imprime o f1
grid_2.fit(features,labels).best_score_O cv também aceita a atribuição de um objeto do StratifiedShuffleSplit, neste caso é necessário a definição da quantidade de n_splits e o tamanho do dataset de testes.
# Exemplo para o uso do StratifiedShuffleSplit.
# Importação do módulo do StratifiedShuffleSplit.
from sklearn.model_selection import StratifiedShuffleSplit
# Usando o constructor para criar o objeto sss
sss = StratifiedShuffleSplit(n_splits = 20, # 20 simulações.
test_size = 0.2, # 20% do dataset será de testes.
random_state = 42) # Permitir a reprodutibilidade.
# Criando um objeto do GridSearchCV
grid_3 = GridSearchCV(estimator = clf,
param_grid = parametros,
cv = sss,
scoring = 'f1')
# Imprime o f1
grid_3.fit(features,labels).best_score_Por fim, há a opção de não usar o cv do GridSearchCV, isto seria feito omitindo-o.
# Exemplo do GridSearchCV sem cv. Demanda um cv manual.
# Criando um objeto do GridSearchCV sem cv.
grid_4 = GridSearchCV(estimator = clf,
param_grid = parametros,
scoring = 'f1')
# Imprime o f1
grid_4.fit(features,labels).best_score_Note que nessas alternativas de cross validation o objetivo é usar métricas para a escolha do modelo que não sejam superestimadas, evitando assim o problema de overfitting.
Scoring
Cada simulação terá como base de avaliação o scoring, e a configuração básica seria a definição de uma das métricas:
- recall;
- precision;
- accuracy, e/ou;
- f1 ou fbeta_score.
Logo, os resultados apresentados no atributo .cv_results_ cujas colunas possuam o sufixo _score referem-se ao scoring definido, para os exemplos anteriores usou-se o f1.
Contudo, há casos onde se necessita a avaliação de não só de um parâmetro, mas de vários. Dessa maneira, introduz-se o make_scorer (leia a documentação do make_scorer), com esse módulo é possível fazer com que o GridSearchCV calcule diversos parâmetros.
# Importando o Make Scorer
from sklearn.metrics import make_scorer
# Importando os módulos de cálculo de métricas
from sklearn.metrics import precision_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import fbeta_score
# Criando um dicionário com as métricas que desejo calcular.
meus_scores = {'accuracy' :make_scorer(accuracy_score),
'recall' :make_scorer(recall_score),
'precision':make_scorer(precision_score),
'f1' :make_scorer(fbeta_score, beta = 1)}
# Exemplo para o uso scoring igual ao meus_scores.
grid_5 = GridSearchCV(estimator = clf,
param_grid = parametros,
cv = 5,
scoring = meus_scores, # É o meus_scores
refit = 'f1') # Observe que foi configurado para f1Espera-se que o grid_5 possua novas colunas das quais tenha sufixos accuracy, recall, precision e f1. Vamos imprimir os nomes das colunas.
# Imprime os nomes das colunas que estão armazenadas no grid_5.
pd.DataFrame(grid_5.cv_results_).columns.tolist()['mean_fit_time',
'std_fit_time',
'mean_score_time',
'std_score_time',
'param_learning_rate',
'param_n_estimators',
'params',
'split0_test_accuracy',
'split1_test_accuracy',
'split2_test_accuracy',
'split3_test_accuracy',
'split4_test_accuracy',
'mean_test_accuracy',
'std_test_accuracy',
'rank_test_accuracy',
'split0_train_accuracy',
'split1_train_accuracy',
'split2_train_accuracy',
'split3_train_accuracy',
'split4_train_accuracy',
'mean_train_accuracy',
'std_train_accuracy',
'split0_test_recall',
'split1_test_recall',
'split2_test_recall',
'split3_test_recall',
'split4_test_recall',
'mean_test_recall',
'std_test_recall',
'rank_test_recall',
'split0_train_recall',
'split1_train_recall',
'split2_train_recall',
'split3_train_recall',
'split4_train_recall',
'mean_train_recall',
'std_train_recall',
'split0_test_precision',
'split1_test_precision',
'split2_test_precision',
'split3_test_precision',
'split4_test_precision',
'mean_test_precision',
'std_test_precision',
'rank_test_precision',
'split0_train_precision',
'split1_train_precision',
'split2_train_precision',
'split3_train_precision',
'split4_train_precision',
'mean_train_precision',
'std_train_precision',
'split0_test_f1',
'split1_test_f1',
'split2_test_f1',
'split3_test_f1',
'split4_test_f1',
'mean_test_f1',
'std_test_f1',
'rank_test_f1',
'split0_train_f1',
'split1_train_f1',
'split2_train_f1',
'split3_train_f1',
'split4_train_f1',
'mean_train_f1',
'std_train_f1']
Conforme esperado houve o cálculo de todas as métricas definidas no dicionário meus_scores. Uma maneira de facilitar a análise é fazendo o subset dos resultados para apenas imprimirem as colunas de interesse.
# Fazendo uma subamostragem.
pd.DataFrame(grid_5.cv_results_)[['params',
'mean_test_recall',
'mean_test_precision',
'mean_test_f1']]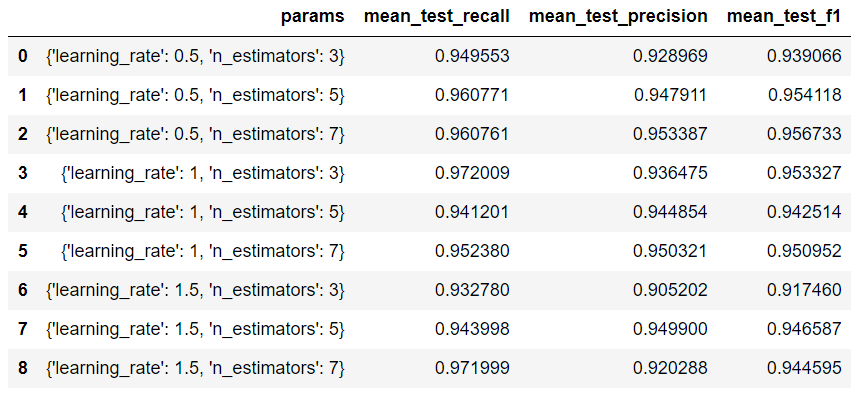
Vamos visualizar quais são os melhores parâmetros com base no refit definido.
# Imprime os melhores parâmetros.
grid_5.fit(features,labels).best_params_{'learning_rate': 0.5, 'n_estimators': 7}
Note que quando há apenas uma métrica é fácil encontrar a melhor solução, pois você escolherá aquele conjunto de parâmetros que gerou a melhor métrica. Contudo, quando há o uso de muitas métricas o GridSearchCV não terá condições de escolher automaticamente, pois existe um trade-off entre as métricas, dessa maneira é necessário a configuração do refit para que o GridSearchCV saiba qual métrica definir como melhor conjunto de parâmetros.
Porém, ao definir o refit e fazer a escolha dos parâmetros usando .best_params_ o resultado fornecido não leva em consideração as outras métricas que não seja aquela definida no refit.
Conclusões
O GridSearchCV é uma ferramenta que automatiza muito das etapas repetitivas do processo de tuning, contudo há diversas peculariedades no uso dela que a tornam um pouco traiçoeira.
Tenha em mente que o refit necessário quando se usa o make_scorer pode não levar em consideração todas as métricas para selecionar a melhor solução, sendo assim só a métrica definida no refit usada para eligir os melhores parâmetros.
Foi disponibilizado um Jupyter Notebook (via Binder ![]() ) com diversas implementações do
) com diversas implementações do GridSearchCV, onde há detalhes que foram omitidos nesse post.